
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- topic
- etl
- Salting
- off heap memory
- backfill
- Kubernetes
- Spark Caching
- redshift
- 빅데이터
- Airflow
- Spark SQL
- mysql
- 데이터 파이프라인
- aws
- Spark 실습
- KDT_TIL
- Docker
- Dag
- SQL
- Spark
- spark executor memory
- Spark Partitioning
- Speculative Execution
- disk spill
- CI/CD
- k8s
- colab
- Kafka
- AQE
- DataFrame Hint
- Today
- Total
JUST DO IT!
Spark Partitioning과 AQE 알아보고 실습하기 - TIL230725(2) 본문
📚 KDT WEEK 17 DAY 2 TIL(2)
- Dynamic Partition Pruning
- Spark Partition 수 조절하기 - Repartition & Coalesce
- DataFrame Hint
- AQE
🟥 Dynamic Partition Pruning
비 Partition 테이블에 적용된 필터링을 Partition 테이블에 적용해보는 것
일반적으로 큰 데이터셋에 조건문(WHERE)을 적용함으로써 큰 데이터를 먼저 작게 필터링하는 것이 효율적이다.
아래 이미지는 orders 테이블이 파티션이 있는 큰 테이블이고, date가 파티션이 없는 작은 테이블일 때,
사용자가 실수로 date 테이블에 조건문을 걸었을 때 자동으로 수정되는 과정이다.

기본 설정은 True로 되어있지만, 다음의 명령어를 입력하면 False로 바꿀 수도 있다.
spark.conf.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "false") # OFF
🟦 Spark Partiton 수 조절 - Repartition과 Coalesce
1. Repartition
- 파티션 수를 증가시켜 병렬성을 증대
- 굉장히 큰 파티션이나 Skew 파티션의 크기 조절
- 하지만 파티션의 수가 너무 많아지면 태스크 스케줄링의 오버헤드 등의 이슈 발생
- Shuffling이 발생하므로 불필요하게 사용될 경우 오히려 시간과 비용이 증가
Repartition 사용 방법(Hash 기반)
- repartition(5)
- rapartition(5, "city") # city 컬럼을 기준으로 5개의 파티션으로 repartition, 컬럼은 여러 개도 입력 가능
- repartition("city") # spark.sql.shuffle.partitions 값에 따라 repartition, AQE를 사용한다면 다를 수 있음
- repartitionByRange(numPartitions, *cols) # 지정된 컬럼 값의 범위를 기준으로 나눔, 알아서 샘플링해서 나눈다.
2. Coalesce
- 파티션의 수를 줄이는 용도로, 로컬 파티션들을 Merge
- Shuffling이 발생하지 않지만, 파티션을 합치는 과정에서 Skew 파티션이 발생할 수 있음
> Repartition 실습
# order 테이블의 파티션별 몇 개의 데이터가 저장되었는지 확인해보기
from pyspark.sql.functions import spark_partition_id
spark.table("order").groupBy(spark_partition_id()).count().show()
# 라운드로빈형태로 균등하게 10개의 파티션으로 리파티션됨
order_10 = spark.table("order").repartition(10).cache()
order_10.groupBy(spark_partition_id()).count().show()
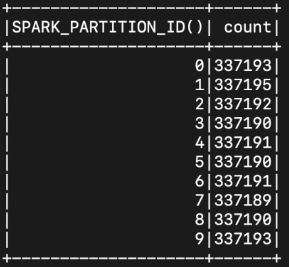
# "sku" 컬럼으로 리파티션
sku_df = spark.table("order").repartition("sku")
# AQE가 활성화되어 있지 않으면 spark.sql.shuffle.partitions 값에 따라 리파티션
# 하지만 기본적으로 활성화되어있기 때문에 알아서 최적화
sku_df.groupBy(spark_partition_id()).count().show()
🟧 DataFrame 관련 힌트
Spark SQL Optimizer에게 Execution plan을 만듬에 있어 특정한 방식을 사용하도록 제안하는 것
1. Partitioning 관련 힌트
어떤 방식으로 Partitioning을 하고싶은지 보낼 수 있다.
ex)
COALESCE, REPARTITION, REPARTITON_BY_RANGE를 사용할 수 있고, 뒤의 인자로 파티션 개수와 컬럼을 받을 수 있다.
REBALANCE라는 옵션도 있는데, 파일의 크기를 최대한 비슷하게 만들어서 저장해주는 옵션이다.(AQE 필요)
2. Join 관련 힌트
Join 방식에 관련된 힌트를 제공한다.
옵션으로 BROADCAST, MAPJOIN, MERGE(기본), SHUFFLE_HASH(Full Outer Join은 불가), SHUFFLE_REPLICATE_NL 등이 있다.
힌트 사용 방식
1. DataFrame API
일반적인 DataFrame Operation 뒤로 .hint를 사용함으로써 Optimizer에게 힌트를 제공한다.
df1.join(df2, "id", "inner").hint("COALESCE", 3)
df1.join(df2.hint("broadcast"), "id", "inner").hint("COALESCE", 3) # JOIN 힌트를 추가한 경우
2. Spark SQL
/*+ hint [, ...] */ 를 쿼리문안에 삽입하여 사용한다.
SELECT /*+ REPARTITION(3) */ * FROM TABLESELECT /*+ BROADCAST(table1) */ * FROM table1 JOIN table2 ON table1.key = table2.key
🟩 AQE (Adaptive Query Execution)
Spark 3.2부터 기본으로 적용되는 최적화 테크닉
Partition의 수가 적으면 병렬성이 떨어지고 OOM과 disk spill의 가능성을 높이고,
Partition의 수가 많으면 task scheduler와 task 생성 관련된 오버헤드가 생기며 네트워크 병목을 초래한다.
Spark Engine Optimizer가 알아서 Partition의 수를 결정할 수 있다면? >> AQE
AQE는 기존의 parsing time 최적화뿐만 아니라 runtime 최적화까지 병행되어 더 효율적인 최적화를 추구한다.
"Dynamic query optimization that happens in the middle of query execution based on runtime statistics"
다시말해 AQE는 동적으로 쿼리 플랜을 바꾸는데, 그 시점이 Shuffling을 하기 전후(Staging)이다.
Stage DAG를 순차적으로 실행해보고, 매번 새로운 최적화 기회가 있는지 조사한다.
AQE가 필요한 경우들
- Shuffling후 Partition의 수를 동적으로 조정하기
- Join Plan 동적으로 변경하기(runtime 통계를 가져오므로 가능)
- Skew Join 최적화
⚙ AQE 동작
1. Dynamically coalescing shuffle partitions
기본적으로 Job을 실행하면서 내부적으로 많은 수의 파티션을 일부러 생성하고, 매 Stage가 종료될 때마다 필요하다면 자동으로 Coalesce를 수행하면서 적당한 수의 파티션 수를 맞춰가는 방식이다.
첫 파티션의 수는 spark.sql.adaptive.coalescePartitions.initialPartitionNum 값을 따르지만, 기본값은 없어서
기본적으로 spark.sql.shuffle.partitions 의 값을 따른다.
아래 그림은 Shuffle후에 파티션의 수가 많다고 판단해서 COALESCE 동작을 추가하는 모습이다.
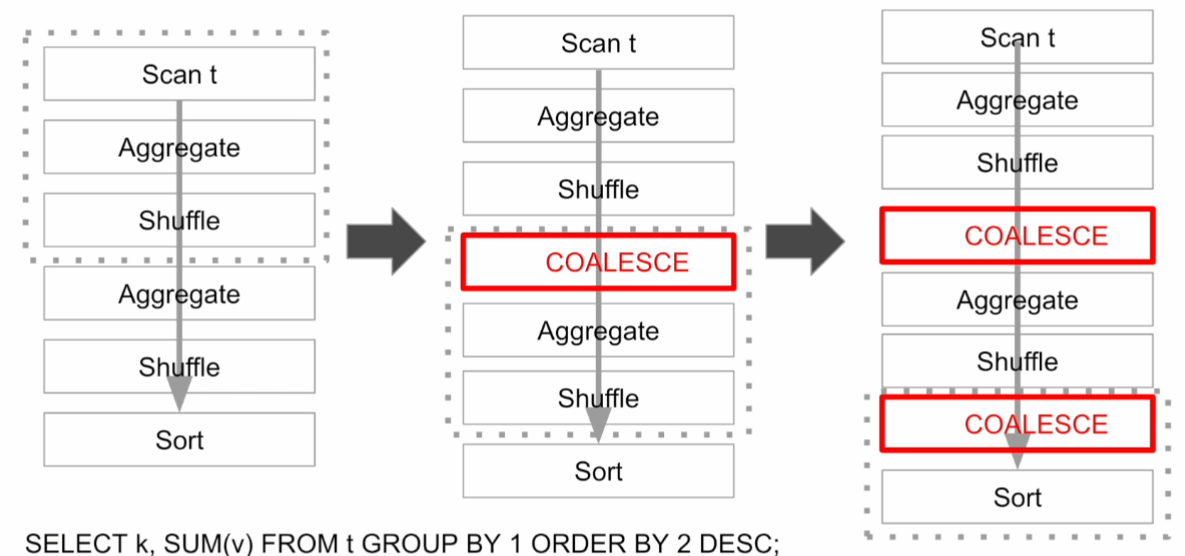
이는 아래의 설정 변수에 따라 조절된다. 괄호 값은 기본값이다.
- spark.sql.adaptive.coalescePartitions.enabled : 셔플 후 파티션 수를 동적으로 줄인다. (True)
- spark.sql.adaptive.coalescePartitions.parallelismFirst : 병렬성을 보장할 것인지 정한다. 두 경우로 나뉜다. (True)
- True인 경우 > spark.sql.adaptive.coalescePartitions.minPartitionSize 값에 따라 Coalescing 결정 (1MB)
- .minPartitionSize는 Coalescing 후 파티션의 최소 크기로써, 이 값보다 파티션의 크기가 작으면 Coalesce
- False인 경우(공식문서 추천) > spark.sql.adaptive.advisoryPartitionSizeInBytes 값으로 맞춰서 파티셔닝 (64MB)
- .advisoryPartitionSizeInBytes는 셔플링 후 파티션 수를 줄일 때 목표로 하는 파티션의 크기이다.
- True인 경우 > spark.sql.adaptive.coalescePartitions.minPartitionSize 값에 따라 Coalescing 결정 (1MB)
2. Dynamically switching join strategies
runtime 통계를 통해 Join 플랜을 동적으로 바꿔 다시 실행하는 방법
Static Query Plan(처음 기본 플랜)이 여러 이유로 BHJ(Broadcast Hash Join) 기회를 놓친 경우에 효율적인 방법이다.
Shuffling 후 AQEShuffleRead를 수행하여 알맞는 Join 방식으로 변경한다. Join 방식에 맞는 셔플링을 다시 실행하게된다.
- spark.sql.join.preferSortMergeJoin : Join시 Sort Merge Join 기본 사용 여부 (True)
- spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold : Hash Join시 파티션 별 해시맵 최대 크기 (0)
- spark.sql.adaptive.autoBroadcastJoinThreshold : Broadcast 가능한 데이터프레임 최대 크기 (없음), -1이면 사용x
- spark.sql.autoBroadcastJoinThreshold와 기본값이 동일하고, AQE 활성화 필요
- spark.sql.adaptive.autoBroadcastJoinThreshold 와 spark.sql.autoBroadcastJoinThreshold 의 차이는 각각 AQE에서 BroadCast Join 판단에 사용하고, Shuffling 전에 처음부터 BroadCastJoin이 필요한지 확인하는 변수이다.
3. Dynamically optimizing skew joins
Skew 파티션으로 인한 성능 문제를 해결하기 위해 AQE가 최적화하는 방법
Skew 파티션의 존재 여부 파악 후, Skew 파티션을 작게 나누고 상대 조인 파티션을 중복 생성하여 조인을 수행한다.
Skew Partition인지 판단하는 조건은 다음의 설정 변수를 모두 만족해야 AQE가 Skew Partition으로 판단한다.
- spark.sql.adaptive.skewJoin.skewedPartitionFactor : 중간 파티션 크기보다 이 값의 배수만큼 한다. (5)
- spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes : 이 값보다 큰 크기이다. (256(MB))
그리고 이 기능을 사용하려면 spark.sql.adaptive.skewJoin.enabled를 True로 주어야 한다.
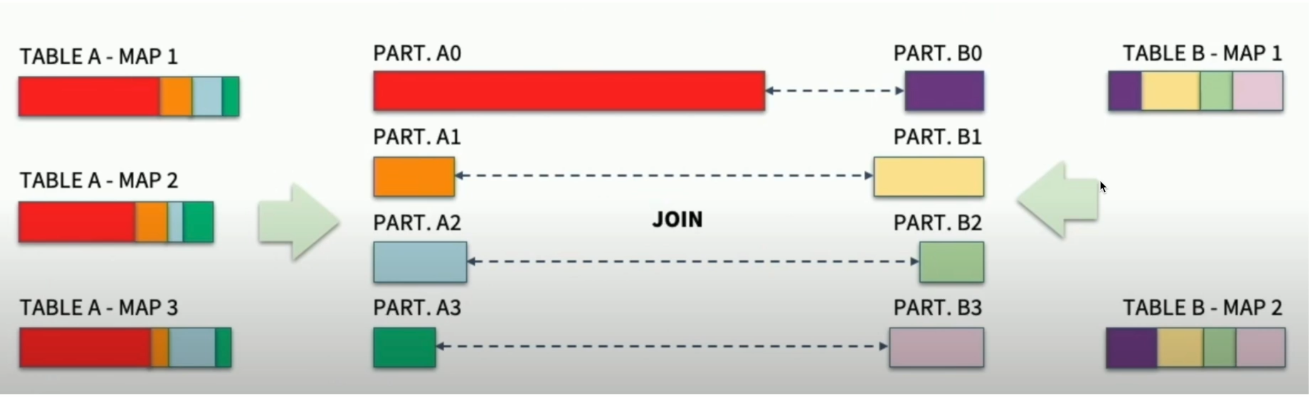
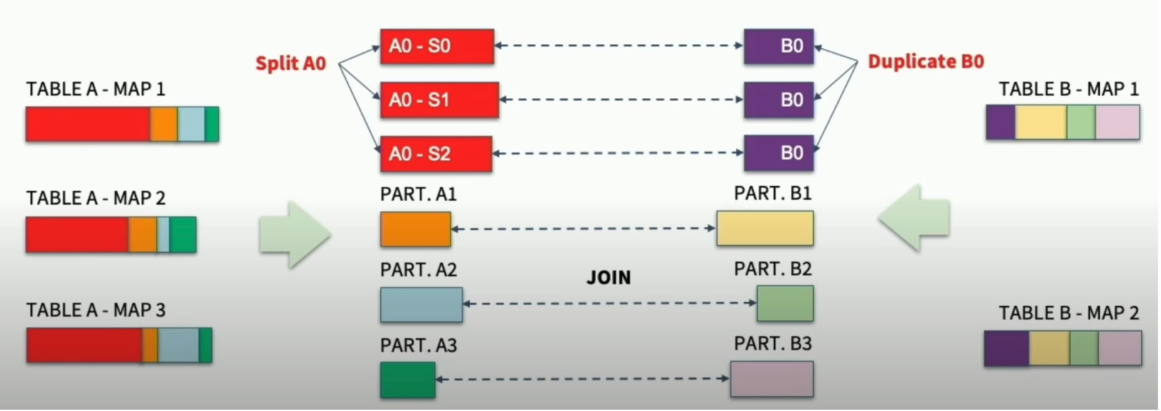
Skew Partition으로 판단된 Partition.A0는 여러 개의 파티션으로 나누어진다.
그리고 원래 조인되려던 PART.B0이 여러 개의 중복 파티션으로 복제되어 각각 조인하게 된다.
'TIL' 카테고리의 다른 글
| Spark에서 데이터 Caching 하는 방법, 실습해보기! - TIL230725 (0) | 2023.07.25 |
|---|---|
| Spark 기능과 스케줄링, 메모리 구성 알아보기 - TIL230724 (0) | 2023.07.25 |
| 머신러닝을 위한 확률 기초 - TIL230719 (0) | 2023.07.24 |
| 머신 러닝을 위한 기초 선형 대수 알아보기 - TIL230718 (0) | 2023.07.20 |
| jupyter에서 머신러닝 End to End 실습해보기 - TIL230717 (0) | 2023.07.20 |



