
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- KDT_TIL
- k8s
- Kubernetes
- 빅데이터
- Kafka
- aws
- colab
- backfill
- Speculative Execution
- mysql
- Salting
- Spark Partitioning
- CI/CD
- AQE
- Docker
- Spark
- Spark 실습
- Airflow
- Dag
- DataFrame Hint
- topic
- off heap memory
- redshift
- Spark SQL
- etl
- 데이터 파이프라인
- spark executor memory
- SQL
- disk spill
- Spark Caching
- Today
- Total
JUST DO IT!
Spark 기능과 스케줄링, 메모리 구성 알아보기 - TIL230724 본문
📚 KDT WEEK 17 DAY 1 TIL
- Spark 기타 기능
- Spark 리소스 할당 방식(리소스 스케줄링)
- Spark Executor 메모리 구성
🟥 Spark 기타 기능
1. Broadcast Variable
- 룩업 테이블등을 브로드캐스팅하여 셔플링을 막는 방식 (브로드캐스트 조인과 비슷)
- 모든 노드에 큰 규모의 Input Dataset을 효과적인 방법으로 줄 때 사용한다.
- 룩업 or 디멘션 테이블(10-20MB의 작은 테이블)을 Executor로 전송하는데 사용
- spark.sparkContext.broadcast로 호출
룩업 테이블(파일)을 UDF로 보내는 방법
- Closure : UDF안에서 파이썬 데이터 구조를 사용하는 경우 > Task 단위의 Serialization
- BroadCast : UDF안에서 브로드캐스트된 데이터 구조를 사용하는 경우 > Worker Node단위의 Serialization
이 Closure와 BroadCast 방법은 밑의 예제 코드를 참고하면 이해하기 쉽다.
BroadCast 데이터셋의 특징
- Worker node로 공유되는 변경 불가 데이터이다.
- Worker node별로 한번 공유되고 캐싱된다.
- Task Memory안에 들어갈 수 있는 크기이어야 한다.
ex) 예제코드
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
# UDF
def my_func(code: str) -> str:
# return prdCode.get(code) # Closure, Task단위의 Serialization으로 비효율적
return bdData.value.get(code) # Broadcast, WorkerNode단위의 Serialization으로 효율적
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("Demo") \
.master("local[3]") \
.getOrCreate()
# 작은 데이터(lookup.csv)을 불러와 prdCode에 딕셔너리형태로 저장
prdCode = spark.read.csv("data/lookup.csv").rdd.collectAsMap()
# 딕셔너리 형태의 데이터를 브로드캐스트 변수로 bdData로 저장
# 이 저장된 bdData를 위에서 정의한 UDF에서 사용하게 된다
bdData = spark.sparkContext.broadcast(prdCode)
data_list = [("98312", "2021-01-01", "1200", "01"),
("01056", "2021-01-02", "2345", "01"),
("98312", "2021-02-03", "1200", "02"),
("01056", "2021-02-04", "2345", "02"),
("02845", "2021-02-05", "9812", "02")]
df = spark.createDataFrame(data_list) \
.toDF("code", "order_date", "price", "qty")
spark.udf.register("my_udf", my_func, StringType())
# Product라는 컬럼을 생성하여 UDF에 따라 값 넣기
df.withColumn("Product", expr("my_udf(code)")) \
.show()
2. Accumulators
일종의 전역 변수로, 특정 이벤트의 수를 기록하는데 사용됨 하둡의 카운터와 흡사하다.
보통 비정상적인 값을 레코드의 수를 세는데 사용한다.
특징
- 스칼라로 만들면 이름을 줄 수 있지만, 그 이외에는 불가능하고 이름있어야 Spark Web UI에 나타난다.
- DataFrame/RDD Foreach 방식으로 구현하는 것이 정확하다. (오류 가능성 줄이기)
ex) 예제코드
# 다음 단순 배열을 데이터프레임화
data = [1, 2, 3, 4, 5]
df_test = spark.createDataFrame(data, "int").toDF("value")
# Accumulator
accumulator = spark.sparkContext.accumulator(0)
# .foreach를 사용하면 레코드별로 데이터가 들어가 value를 accumulator에 더하게된다.
def add_to_accumulator(row):
global accumulator
accumulator += row["value"]
df_test.foreach(add_to_accumulator)
print("Accumulator value: ", accumulator.value)

3. Speculative Execution
느린 태스크를 다른 Worker node에 있는 Executor에서 중복 실행
Worker node의 하드웨어 이슈로 느려진 Task라면, 빠른 실행을 보장하나 Data Skew로 인한 느림이라면 리소스 낭비
spark.speculation으로 컨트롤하며, 기본은 False로 비활성화되어 있다.
Speculative Execution 환경변수 (기본값)
- spark.speculation.interval : 느린 태스크 체크 주기 (100ms)
- spark.speculation.multiplier : 일반 태스크들의 실행 시간에 이 변수값을 곱해 느린 태스크 결정 (1.5)
- spark.speculation.quantile : 전체 태스크의 완료율이 이 변수값을 넘으면 느린 태스크 체크 (0.75)
- spark.speculation.minTaskRuntime : 느린 태스크로 특정하는 최소 실행 시간 (100ms)
🟦 Spark 리소스 할당 방식 (리소스 스케줄링)
Spark Application들간의 리소스 할당
- 기반이 되는 리소스 매니저가 결정하게 된다.
- YARN의 경우 FIFO, FAIR(균등히), CAPACITY(우선순위에 따라) 지원
- Static Allocation (기본)
- 한번 리소스를 할당받으면, 해당 리소스를 끝까지 들고가는 것이 기본이다. > 비효율적
- Dynamic Allocation
- 상황에따라 executor를 릴리스하기도하고, 요구하기도 한다.
- 다수의 Spark Application들이 하나의 리소스 매니저를 공유한다면 활성화하는 것이 좋다.
- ex) spark-submit --num-executors 100 --executor-cores 4 --executor-memory 32G
- spark.dynamicAllocation.enabled = true, spark.dynamicAllocation.shuffleTracking.enabled = true 필요
Spark Application안에서 Job들간의 리소스 할당
>> Spark Scheduler : 하나의 Application안에서 잡들에 리소스를 나눠주는 정책
- FIFO : 리소스를 처음 요청한 Job에게 우선순위 (기본방식)
- FAIR : 라운드로빈 방식으로 모든 Job에게 고르게 리소스를 분배
- Pool이란 형태로 리소스를 나눠서 우선순위를 고려한 형태로 사용한다.
- Pool안에서 리소스 분배도 FAIR 혹은 FIFO로 지정 가능하다.

ex) FAIR 예시
fair.xml
<?xml version="1.0"?>
<allocations>
<pool name="production">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>2</minShare>
</pool>
<pool name="test">
<schedulingMode>FIFO</schedulingMode>
<weight>2</weight>
<minShare>3</minShare>
</pool>
</allocations>
fair.py
from pyspark.sql import SparkSession
import threading
import time
# fair.xml에서 pool_name에 해당하는 풀에서 할당
# sparkContext.setLocalProperty는 Thread안에서 사용되어야 한다.
def do_job(f1, f2, id, pool_name, format="json"):
spark.sparkContext.setLocalProperty("spark.scheduler.pool", pool_name)
print(spark.sparkContext.getLocalProperty("spark.scheduler.pool"))
if format == 'json':
df1 = spark.read.json(f1)
df2 = spark.read.json(f2)
else:
df1 = spark.read.csv(f1, header=True)
df2 = spark.read.csv(f2, header=True)
outputs.append(df1.join(df2, id, "Inner").count())
# FAIR Scheduler를 사용할 때는 아래처럼 설정해주면 된다.
spark = SparkSession\
.builder\
.appName("Fair Scheduler Demo")\
.config("spark.sql.autoBroadcastJoinThreshold", "50B")\
.config("spark.scheduler.mode", "FAIR")\
.config("spark.scheduler.allocation.file", "fair.xml")\
.getOrCreate()
outputs = []
# thread를 병렬처리하는 시간 측정해보기
start_time_fifo = time.time()
thread1 = threading.Thread(
target=do_job,
args=(
"small_data/",
"large_data/",
"id",
"production"
)
)
thread2 = threading.Thread(
target=do_job,
args=(
"user_event.csv",
"user_metadata.csv",
"user_id",
"test",
"csv"
)
)
thread1.start()
thread2.start()
thread1.join() # 끝날 때까지 대기하라는 명령어
thread1.join()
end_time_fifo = time.time()
# 소요 시간 출력하기
print(f"Time taken with FAIR Scheduler: {(end_time_fifo - start_time_fifo) * 1000:.2f} ms")
🟨 Spark Executor 메모리 구성
Spark Application = 하나의 Driver + 하나 이상의 Executor
Driver 역할
- main 함수 실행하고 SparkSession과 SparkContext를 생성
- 사용자가 만든 코드를 태스크로 변환하여 DAG 생성
- 리소스 매니저의 도움을 받아 태스크들을 실행하고 관리
- 위 정보들을 Web UI로 노출(4040포트)
Executor의 메모리 구성
Driver 메모리 구성 ex) spark.driver.memory = 4GB
Executor 메모리 구성 ex) spark.executor.memory = 8GB
단, Driver와 Executor에 할당하는 메모리는 YARN을 사용하는 경우 yarn.nodemanager.resource.memory-mb보다 클 수 없다.
Executor에 할당된 메모리는 JVM Heap Memory로써, 3가지의 메모리로 구분된다.
- Reserved Memory : Spark Engine 전용 메모리로써 변경 불가(300MB)
- Spark Memory : 데이터 프레임 관련 작업과 캐싱, 두 가지의 Memory Pool로 나뉜다.
- Storage Memory Pool : Spark 메모리 중 캐싱에 사용되는 메모리
- Executor Memory Pool : DataFrame Operation에 해당하는 메모리
- User Memory : UDF, RDD conversion operation 등
spark.memory.fraction = 0.6처럼 조정하면, Spark Memory에 Reserved Memory 공간(300MB)을 제외한 60퍼센트의 메모리가 할당되고, 나머지가 User Memory에 할당된다.
따라서 User Memory 필요에 따라 spark.memory.fraction 옵션을 조정해주면 좋다.
Executor의 병렬처리
spark.executor.cores = 4로 지정해주면, 하나의 Executor안에 4개의 CPU 슬롯(Thread)가 생겨 병렬처리가 가능해진다.
이 슬롯들은 JVM Heap Memory를 공유하게 된다.

Executor Memory Pool Management > Unified Memory Manager
동작중인 태스크 대상으로 Fair Allocation이 기본 동작으로, 실행중인 태스크가 메모리는 가져가는 구조다.
1개만 실행된다면 하나의 태스크가 모든 메모리를 가져가고, 두 개가 실행된다면 두 태스크가 메모리를 나눠갖는다.
Eviction과 Disk Spill (Unified Memory Manager)
Storage Memory Pool과 Executor Memory Pool은 spark.memory.storageFraction 옵션으로 설정된 비율에 따라 나뉜다.
기본은 0.5이지만, 어느 한쪽에서 메모리가 부족해지면 다른쪽의 메모리를 빌려쓸 수 있다.
하지만 다른쪽 메모리도 부족하면 어떻게 될까?
spark.memory.storageFraction으로 지정된 비율이 지켜지면서 eviction이 발생한다.
eviction은 빌려온 메모리를 다시 되돌려주는 과정을 말하고, 메모리를 다시 되돌려주는 과정에서 메모리에 저장되어 있던 데이터는 디스크로 옮겨지게 된다. 이걸 Disk Spill이라고 부른다.
Disk Spill도 불가능해지면 OOM(Out of Memory)가 발생한다.
이외의 작업에 사용되는 메모리는 어떻게 할당할까?
- spark.memory.offHeap.enabled = True일 때, spark.memory.offHeap.size를 통해 Non-JVM 작업의 별도 메모리를 구성할 수 있다.
- spark.executor.pyspark.memory를 통해 파이썬 프로세스에 지정되는 별도의 메모리를 구성할 수 있지만, 기본값은 0으로써 따로 지정되지 않으면 Non-JVM 메모리(오버헤드 메모리)를 사용한다.
- spark.python.worker.memory를 통해 Py4J에 지정되는 메모리를 조율한다.(기본값 512(MB))
On Heap 메모리와 Off Heap 메모리
이제까지 설명한 메모리가 On Heap 메모리에 해당하고, Spark는 이 On Heap 메모리에서 가장 잘 동작하게 된다.
하지만 JVM Heap Memory는 Garbage collection(동적 메모리 정리)의 대상이 되고, 그에 따라 비용이 발생한다.
이 비용 증가를 막기 위해 같이 사용할 수 있는 메모리가 JVM 밖에 있는 메모리, Off Heap 메모리가 된다.
Off Heap 메모리에는 executor memory 사이즈의 일정 비율로 생성되는 Overhead Memory가 있다.
spark.executor.memory.Overhead 옵션을 통해 비율 조정이 가능하고, 최소 384MB 최대 0.1(10%)이 할당된다.
위에서 Non-JVM 작업을 위한 별도 메모리로 offHeap.size를 조정한다고 언급했었다. 이 메모리도도 Off Heap에 해당한다.
Spark 3.x는 Off Heap memory 작업에 최적화되어 JVM 없이 직접 메모리 관리가 가능하며, DataFrame용으로 사용한다.
따라서 Off Heap 메모리의 크기는 spark.executor.memoryOverhead + spark.offHeap.size와 같다.
ex)
spark.executor.memory = 8GB
spark.executor.memoryOverhead = 0.1

Spark 메모리 이슈 (OOM)
Driver OOM 케이스
- 큰 데이터셋에 collect 실행
- 큰 데이터셋을 Broadcast JOIN
- 태스크가 너무 많이 발생할 때
Executor OOM 케이스
- Data Skew
- executor.cores가 너무 많아 많은 수의 Thread들이 메모리를 공유할 때 > 사용가능한 메모리가 적어져 이슈발생
- 높은 병렬성을 바라고 executor cores수를 너무 늘리면 안되고, 1~5개 정도가 적당하다.
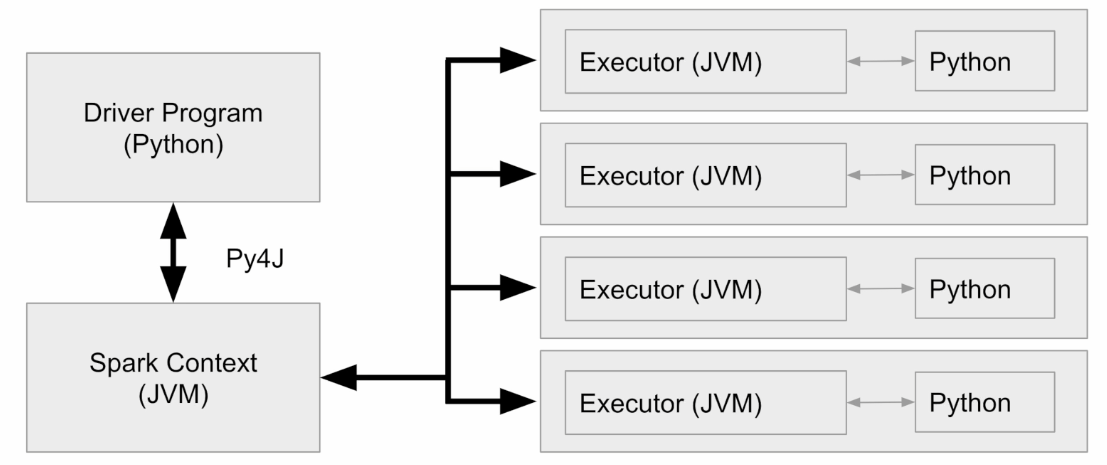
++) JVM과 Python의 통신
Spark은 JVM Application이지만 PySpark은 Python 프로세스로, JVM에서 동작하지 못해 JVM 메모리를 사용할 수 없다.
따라서 위에서 언급한 pyspark.memory(Python 프로세스)와 worker.memory(Py4J)에 따로 메모리를 할당한다.
할당하지 않으면 자동으로 Overhead 메모리를 사용하게된다.
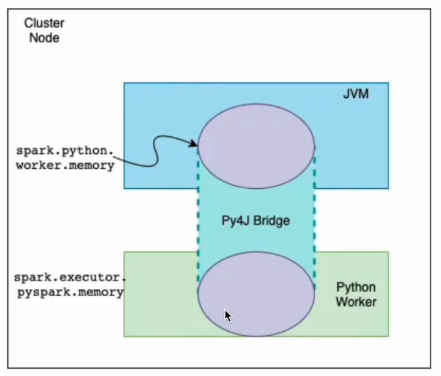
Executor안에는 JVM 프로세스와 Python Worker가 존재하게 되는데,
이 둘간의 오브젝트 serialization/deserialization을 수행해주는 것이 Py4J의 역할이 된다.
'TIL' 카테고리의 다른 글
| Spark Partitioning과 AQE 알아보고 실습하기 - TIL230725(2) (0) | 2023.07.25 |
|---|---|
| Spark에서 데이터 Caching 하는 방법, 실습해보기! - TIL230725 (0) | 2023.07.25 |
| 머신러닝을 위한 확률 기초 - TIL230719 (0) | 2023.07.24 |
| 머신 러닝을 위한 기초 선형 대수 알아보기 - TIL230718 (0) | 2023.07.20 |
| jupyter에서 머신러닝 End to End 실습해보기 - TIL230717 (0) | 2023.07.20 |



