
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- backfill
- aws
- mysql
- Dag
- Spark Caching
- redshift
- topic
- disk spill
- spark executor memory
- Speculative Execution
- Spark 실습
- k8s
- etl
- Spark
- CI/CD
- off heap memory
- DataFrame Hint
- Spark Partitioning
- colab
- SQL
- Spark SQL
- 빅데이터
- Docker
- KDT_TIL
- Kafka
- Kubernetes
- 데이터 파이프라인
- AQE
- Salting
- Airflow
- Today
- Total
JUST DO IT!
jupyter에서 머신러닝 End to End 실습해보기 - TIL230717 본문
📚 KDT WEEK 16 DAY 1 TIL
- 머신러닝 E2E 실습
- 0. 실습 환경 설정
- 1. 테스트 데이터셋 만들기
- 2. 데이터 정제
- 3. 모델 훈련
- 4. 모델 세부 튜닝
- 5. 테스트 데이터셋 평가
- 6. 상용화를 위한 모델 저장
🟥 머신 러닝 End to End 실습
Machine Learning(기계학습) : 경험을 통해 자동으로 개선하는 컴퓨터 알고리즘 연구
캘리포니아 인구조사 데이터를 사용해 캘리포니아 주택 가격 예측모델 만들기
⚒️ 0. 실습 환경 설정
virtualenv를 사용하여 가상환경안에서 작업하도록 한다.
# 원하는 폴더안에서 작업
pip install virtualenv # 가상환경
virtualenv my_env # 원하는 이름 설정
# 가상환경 실행
source my_env/bin/activate # on Linux or macOS
.\my_env\Scripts\activate # on Windows
나의 경우에는 윈도우 Powershell을 통해 작업했는데, activate를 사용해도 가상환경이 실행되지 않았다.
이유는 Powershell이 기본적으로 가상환경 실행을 방지하기 때문이다.
다음의 명령어를 Powershell에서 사용하면 이 설정을 제한없음으로 바꿔줄 수 있다.
Set-ExecutionPolicy -ExecutionPolicy Unrestricted -Scope CurrentUser
정상적으로 가상환경이 실행된다면, (my_env)처럼 설정한 가상환경이름으로 괄호안에 들어가 접속된다.

그리고 가상환경에서 다음의 패키지들을 설치한다. 그리고 실습은 jupyter에서 진행한다.
python -m pip install -U jupyter matplotlib numpy pandas scipy scikit-learn
# 설치가 끝나면 jupyter 노트북 실행
jupyter notebook
데이터셋은 캘리포니아 인구조사 데이터를 사용한다. (굉장히 오래된 데이터로, 학습용이다)
import pandas as pd
# housing.csv 파일 pandas로 불러오기
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
datasets/housing/housing.csv
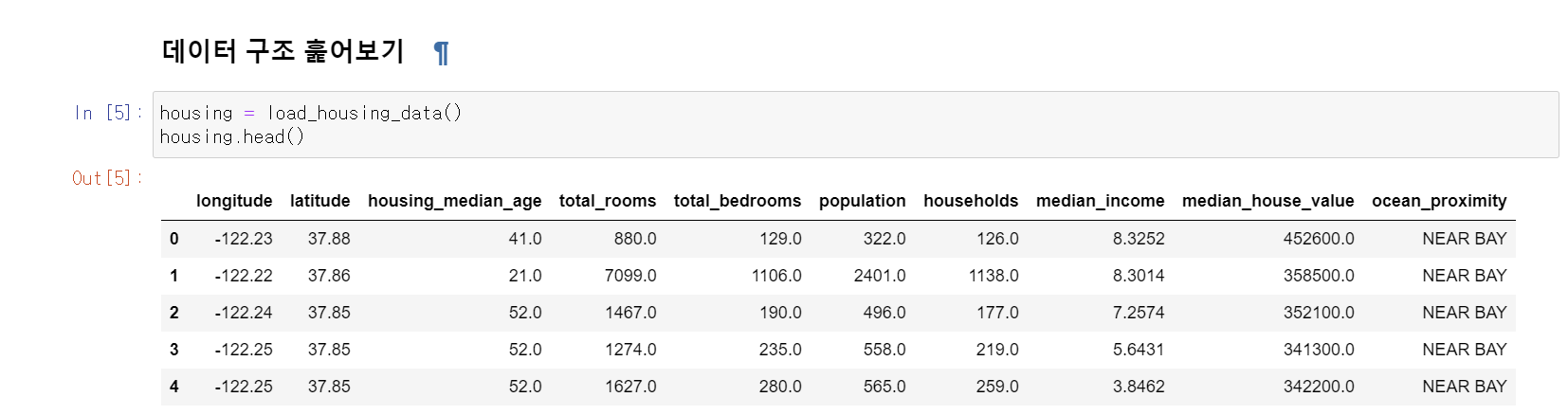
위도와 경도별 가구의 평균나이, 방의 개수부터 평균 수입, 평균 주택 가치등을 알 수 있다.
ocean_proximity는 해안가와 가까운지 나타내는 컬럼이다.
🏗️ 1. 테스트 데이터셋 만들기
좋은 모델을 만들기 위해서는 훈련에 사용되지 않고 모델 평가만을 위한 테스트 데이터셋을 구분하는 것이 좋다.
import numpy as np
np.random.seed(42) # 랜덤 테스트 시드 생성
# 데이터와 테스트 비율을 입력받아 테스트 데이터셋 생성
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data)) # 데이터를 랜덤으로 섞어줌
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
# housing 데이터를 20퍼센트 비율로 테스터 데이터셋 생성
# housing은 csv파일을 pandas.read_csv로 불러온 형태의 데이터
train_set, test_set = split_train_test(housing, 0.2)
or
sklearn에서 제공하는 분할함수 사용
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
여기서 계층적 샘플링을 해주는 것이 테스트 데이터가 전체 데이터를 대표하기에 좋다.
이 경우에도 sklearn에서 제공하는 StratifiedShuffleSplit을 사용한다.
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
이제 훈련 데이터 셋은 strat_train_set을 사용하고, 테스트셋은 strat_test_set을 사용한다.
🪄 2. 데이터 정제
1) 누락된 특성(missing features) 다루기
- 해당 구역을 제거(행을 제거)
- 해당 특성을 제거(열을 제거)
- 어떤 값으로 채우기(0, 평균, 중간값 등)
훈련에는 값이 채워지는 것이 좋으나 데이터의 특성에 따라 적절하게 채워야만 한다.
왜 그 데이터가 누락됬는지를 파악해야 적절한 값을 채울 수 있을 것이다.
먼저, 훈련 데이터셋의 라벨을 따로 복사해둔다.
housing = strat_train_set.drop("median_house_value", axis=1) # drop labels for training set
housing_labels = strat_train_set["median_house_value"].copy()
값의 누락 확인
sample_incomplete_rows = housing[housing.isnull().any(axis=1)].head() # True if there is a null feature
sample_incomplete_rows

total_bedrooms 행의 값이 누락된 데이터가 보인다.
이 데이터의 정제를 위해 아까의 설명한 세 가지 방법을 사용해보자.
sample_incomplete_rows.dropna(subset=["total_bedrooms"]) # total_bedrooms가 누락된 행 제거
sample_incomplete_rows.drop("total_bedrooms", axis=1) # total_bedrooms 행 자체를 제거
# total_bedrooms가 누락되지 않은 값들 중에서 중간 값을 계산하여 채워넣기
# .fillna를 사용하면 누락된 값에 해당 값이 채워진다.
median = housing["total_bedrooms"].median()
sample_incomplete_rows["total_bedrooms"].fillna(median, inplace=True)
sklearn이 제공하는 SimpleImputer 사용하기
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
# 중간값은 수치형 특성에서만 계산될 수 있기 때문에 텍스트 특성을 제외한 복사본을 생성
housing_num = housing.drop("ocean_proximity", axis=1)
imputer.fit(housing_num) # .fit 함수로 인자로 넣은 데이터의 설정값(median)이 imputer에 들어간다.
X = imputer.transform(housing_num) # 누락된 값 채워넣기, X는 NumPy array가 된다.
housing_tr = pd.DataFrame(X, columns=housing_num.columns, index=housing.index) # pandas DataFrame으로 되돌리기
결과

이런 숫자형 데이터는 이렇게 다루면 되지만, 텍스트와 범주형 데이터는 어떻게 다루고 학습시켜야할까?
2) 텍스트와 범주형 데이터 다루기
모듈을 사용하여 간단하게 텍스트를 숫자형태로 바꿀 수 있다.
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat) # fit_transform 함수는 각각의 텍스트를 숫자로 매핑하고 변환한다.
housing_cat_encoded[:10]
결과
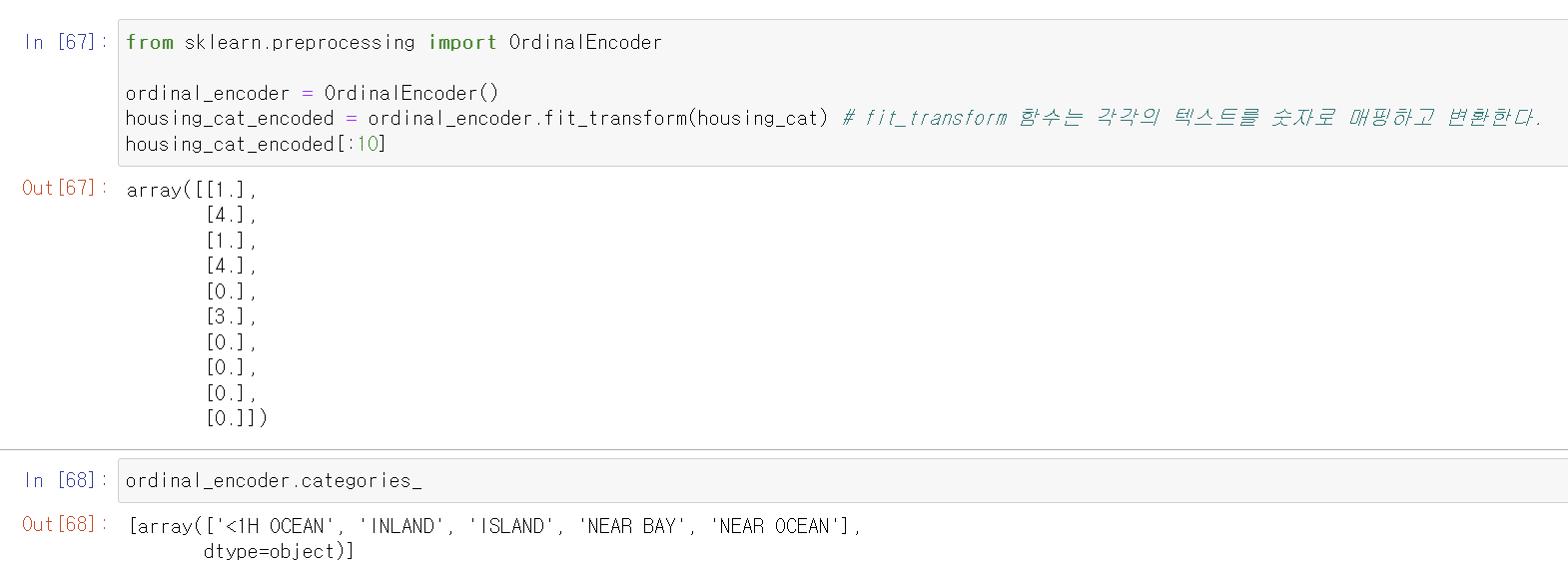
하지만 단순히 배열로 나타내서 해당하는 순서를 넣었을 뿐이다.
모델이 더 나은 학습을 하려면 바다에 가까운 위치부터 나열해서 숫자가 낮을수록 바다와 가깝다는 의미를 넣으면 좋을 것 같다.
각 카테고리별로 컬럼으로 나눠버리는 방법도 있다. (One-hot encoding)
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot.toarray()

모델에게는 파라미터를 여러 개 주는 것이 학습에 좋다고 하니, 이러한 방법도 좋을 것 같다.
3) 나만의 변환기(Custom Transformer)로 만들기
sklearn이 제공하는 BaseEstimator, TransformerMixin을 사용해서 커스텀으로 제작해보자.
변환기에는 fit()과 transform()을 꼭 구현해야한다.
rooms_per_household, population_per_household 두 개의 새로운 특성을 데이터셋에 추가하며 add_bedrooms_per_room = True로 주어지면 bedrooms_per_room 특성까지 추가하도록 구현했다.
from sklearn.base import BaseEstimator, TransformerMixin
# column index
rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X):
rooms_per_household = X[:, rooms_ix] / X[:, households_ix] # 해당 열끼리 나누기 > 각 원소끼리 나눠짐
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)
입력이 Numpy 형태(housing.values)로 들어가서 Numpy형태로 리턴되었기 때문에 DataFrame으로 변환해야 한다.
housing_extra_attribs = pd.DataFrame(
housing_extra_attribs,
columns=list(housing.columns)+["rooms_per_household", "population_per_household"],
index=housing.index)
housing_extra_attribs.head()

여러 개의 변환이 순차적으로 이루어져야 할 경우 Pipeline class를 사용하면 편하다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# StandardScaler는 값의 표준화(평균이 0, 분산이 1)
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
Pipeline 특성은 다음과 같다.
- 이름, 추정기 쌍의 목록형태로 Pipeline을 구현한다.
- 마지막 단계를 제외하고 모두 변환기여야 한다.(fit_transform() method를 가지고 있어야 함)
- 파이프라인의 fit() method를 호출하면 모든 변환기의 fit_transform() method를 순서대로 호출하면서 한 단계의 출력을 다음 단계의 입력으로 전달하고, 마지막 단계에서는 fit() method만 호출한다.

모든 열이 아닌 각 열마다 다른 파이프라인을 적용할 수도 있다.
sklearn의 ColumnTransformer를 사용하면 된다.
from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num) # housing_num의 모든 특성 리스트를 저장
cat_attribs = ["ocean_proximity"] # ocean_proximity 특성만을 리스트로 저장
# 세번째 인자로 특성이 담긴 리스트를 넘김으로써 각 열마다 다른 Transform 함수 적용 가능
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(housing)
🏃♂️ 3. 모델 훈련
1) 선형 회귀 모델

sklearn의 LinearRegression을 사용하면 쉽게 구현할 수 있다.
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
학습된 모델의 w값, 즉 예측에 필요한 수치를 직접 확인해 볼 수도 있다.

학습된 모델을 토대로 몇 개의 데이터를 예측시켜 얼마나 잘 예측되는지 확인해보자.
# 몇 개의 샘플에 대해 데이터변환 및 예측을 해보자
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
# 선형 회귀 모델의 Predict 함수를 사용해서 예측
print("Predictions:", lin_reg.predict(some_data_prepared).round(decimals=1))
print("Labels:", list(some_labels)) # 정답
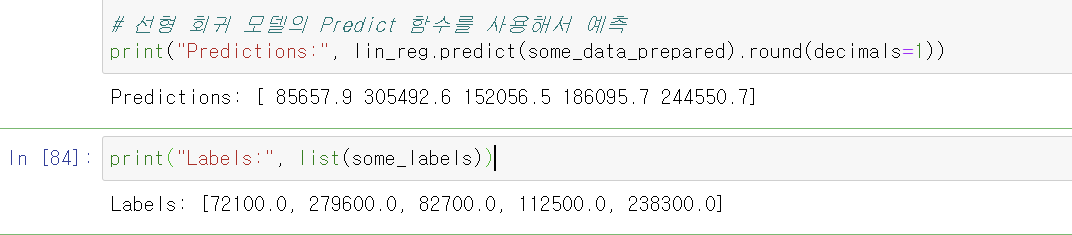
전체 데이터에 대해 예측값이 얼마나 벗어났는지 확인할 에러값(RMSE)도 측정할 수 있다.
# 평균 에러값 계산 (훈련 데이터셋에 대해)
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)

RMSE값이 크게 나오는 경우, 이를 과소적합이라고 한다.
특성들이 충분한 정보를 제공하지 못했거나, 모델이 강력하지 못하면 이러한 결과가 나온다.
2) DecisionTreeRegressor
이번에는 비선형모델인 DecisionTreeRegressor 모델을 사용해서 학습시켜보자.
이 모델도 sklearn을 사용하면 간단한 코드로 학습시킬 수가 있다.
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(random_state=42)
tree_reg.fit(housing_prepared, housing_labels)
이번에도 학습데이터에 대해 에러값을 측정해보자.
# 예측
housing_predictions = tree_reg.predict(housing_prepared)
# 에러, 학습데이터에 대해서는 에러 x
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)

0이 나왔지만 이는 학습데이터에 대한 에러값이기 때문에 그냥 모델이 학습데이터에 대해서만 완벽히 적응한 것이다.
좀 더 정확한 테스트를 위해서는 학습에 사용하지 않은 테스트 데이터셋 검증이나, 교차 검증을 사용하면 된다.
테스트 데이터셋 검증은 위와 동일하게 수행하면 되므로 패스하고, 교차 검증을 해보자.
교차 검증은 학습데이터셋의 일부를 학습에서 제외시킨 뒤 에러 검증에 사용하는 작업을 반복하는 방법이다.
아래 그림에서는 매 Iteration마다 각기 다른 데이터 5분의 1을 검증데이터로 사용하여 이들의 평균 에러값을 계산한다.

sklearn에서 제공하는 cross_val_score을 사용하면 간단하게 계산할 수 있다.
cv값을 조정하여 데이터 조각 개수(반복 횟수)를 직접 정하면 된다.
# 교차검증
# sklearn의 cross_val_score 사용, cv로 데이터 조각 개수 정하기
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels, scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
display_scores(tree_rmse_scores)

교차 검증을 했더니 에러값이 꽤 큰 값으로 나왔다.
3) RandomForestPrediction 모델
이 모델은 트리 구조의 예측기를 여러 개 사용하여 그 예측값의 평균을 사용하는 모델이다.

일반적으로 하나의 트리 구조를 사용한 모델보다 여러 개를 사용한 모델의 성능이 높다고 한다.
이 모델 또한 sklearn을 사용하면 단순하게 구현이 가능하다.
# Tree가 여러 개인 형태
from sklearn.ensemble import RandomForestRegressor
# 100개의 트리를 사용
forest_reg = RandomForestRegressor(n_estimators=100, random_state=42)
forest_reg.fit(housing_prepared, housing_labels)
그리고 성능 검증을 위해 교차 검증을 수행해보았다.

위에서 DecisionTreeRegressor 모델을 교차 검증했던 수치(71629)보다 더 적게(50435) 나왔다.
그렇다는건, 더 좋은 모델이라고 할 수 있는 것이다.
🪛 4. 모델 세부 튜닝
1) GridSearhCV
모델이 수치를 조절하는 것이 아니라, 사람이 직접 수치를 조절하여 모델의 성능을 올릴 수도 있다.
이때, 사람이 직접 세팅한 값을 하이퍼파라미터라고 한다.
하지만 여러 개의 수치를 매번 조절하여 모델을 학습시키기에는 굉장한 노력이 필요할 것이다.
이러한 수고를 덜어주는 기능도 sklearn의 GridSearchCV을 사용하면 쉽다.
# 하이퍼파라미터 튜닝
# sklearn의 GridSearchCV을 사용하면 하이퍼파라미터 조합을 모델에 전달해주어 알아서 하이퍼파라미터 튜닝해줌
from sklearn.model_selection import GridSearchCV
param_grid = [
# try 12 (3×4) combinations of hyperparameters
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
# then try 6 (2×3) combinations with bootstrap set as False
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
# 아까 사용한 RandomForestRegressor 모델과 비교를 위해 동일한 수치
forest_reg = RandomForestRegressor(random_state=42)
# 설정한 파라미터에 대한 여러 시도의 학습과, cv=5 만큼의 교차검증까지 수행
grid_search = GridSearchCV(forest_reg, param_grid, cv=5, scoring='neg_mean_squared_error', return_train_score=True)
grid_search.fit(housing_prepared, housing_labels)
params_grid 리스트안의 dictionary 별로 파라미터를 조합하여 모델을 만들어본다.따라서 첫 번째 dictionary에서 3x4 = 12(n_estimators 수 x max_features 수)개의 조합을 만들어내고,두 번째 dictionary에서 bootstrap = False인 상태에서 2x3 = 6개의 조합을 만들어내어,총 12+6 = 18개의 모델을 만들게된다.
또한 각 파라미터별 모델의 교차 검증까지 수행하여 어떤 파라미터를 가진 모델의 성능이 좋은지 판단하게 된다.이는 GridSearchCV 모델을 사용하면서 인자로 cv 값을 입력하여 데이터 조각의 개수를 조절할 수 있다.
학습이 완료되었다면 베스트 파라미터를 뽑아보자.

또한 어떤 조합에서 어떤 스코어가 나타났는지 확인할 수도 있다.

2) Randomized Search
하이퍼파라미터 조합의 수가 큰 경우에는 일정 범위안의 파라미터를 지정한 횟수만큼 평가하는 방법이다.
# 랜덤하게 파라미터를 설정해서 학습하도록 함
# 몇 번의 시도후에 가장 좋은 파라미터 찾기
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {
'n_estimators': randint(low=1, high=200),
'max_features': randint(low=1, high=8),
}
# n_iter는 조합의 수, 10개의 랜덤한 조합을 시도해봄
forest_reg = RandomForestRegressor(random_state=42)
rnd_search = RandomizedSearchCV(forest_reg, param_distributions=param_distribs,
n_iter=10, cv=5, scoring='neg_mean_squared_error', random_state=42)
rnd_search.fit(housing_prepared, housing_labels)
그리고 이번에도 어떤 조합에서 어떤 스코어가 나타났는지 확인해보자.

🕶️ 5. 테스트 데이터셋 평가
마지막으로 테스트 데이터셋으로 최종 평가를 해보자.
# 가장 좋은 모델을 final_model로 지정
final_model = grid_search.best_estimator_
# 테스트 데이터셋의 라벨 제거 : X_test
# 테스트 데이터셋의 정답 : y_test
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
# 모델에 넣기위해 학습데이터와 같이 파이프라인으로 transform 작업
# transform후 final_model로 예측작업
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
# 에러 계산
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)

📦 6. 상용화를 위한 모델 저장
전처리와 예측이 한번에 동작할 수 있는 하나의 파이프라인을 만들어, pkl 파일형태로 저장한다.
# 전처리+예측 둘 다 있는 하나의 파이프라인 만들기
full_pipeline_with_predictor = Pipeline([
("preparation", full_pipeline),
("linear", LinearRegression())
])
# 사용방법
# full_pipeline_with_predictor.fit(housing, housing_labels)
# full_pipeline_with_predictor.predict(some_data)
my_model = full_pipeline_with_predictor
# 모델 파일 저장
import joblib
joblib.dump(my_model, "my_model.pkl")
# 모델 파일 사용
my_model_loaded = joblib.load("my_model.pkl")
my_model_loaded.predict(some_data)
+) 새로운 특성을 넣었을 때, 어떤 특성이 중요한지 파악할 수 있다.
# 새로운 특성을 넣었을 때 어떤 특성이 중요한지 파악하기
feature_importances = grid_search.best_estimator_.feature_importances_
feature_importances
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
#cat_encoder = cat_pipeline.named_steps["cat_encoder"] # old solution
cat_encoder = full_pipeline.named_transformers_["cat"]
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True)

'TIL' 카테고리의 다른 글
| 머신러닝을 위한 확률 기초 - TIL230719 (0) | 2023.07.24 |
|---|---|
| 머신 러닝을 위한 기초 선형 대수 알아보기 - TIL230718 (0) | 2023.07.20 |
| Kafka Producer 및 Consumer 실습해보기 with Python (+ksqlDB) - TIL230713 (0) | 2023.07.14 |
| Kafka 알아보고 설치해보기 - TIL230712 (0) | 2023.07.14 |
| 빅데이터의 실시간 처리 -TIL230710 (0) | 2023.07.11 |



