
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Docker
- off heap memory
- Speculative Execution
- Spark Partitioning
- KDT_TIL
- k8s
- CI/CD
- Kafka
- Kubernetes
- DataFrame Hint
- colab
- etl
- disk spill
- SQL
- Dag
- redshift
- Spark SQL
- Spark Caching
- aws
- Spark 실습
- Airflow
- Salting
- AQE
- 빅데이터
- Spark
- topic
- mysql
- spark executor memory
- backfill
- 데이터 파이프라인
- Today
- Total
JUST DO IT!
Colab에서 Spark SQL 간단 실습해보기(+ Hive 메타스토어) - TIL230705 본문
📚 KDT WEEK 14 DAY 3 TIL
- SparkSQL
- SparkSQL Colab 실습
- Hive 메타스토어
- 유닛 테스트해보기
🟥 SparkSQL
구조화된 데이터 처리를 위한 Spark 모듈
- 데이터프레임에 테이블 이름을 지정하면, SQL 함수 사용 가능
- HQL(Hive Query Language)와 호환 제공하여, Hive 테이블들을 읽고 쓸 수 있다
- SQL이 데이터프레임 작업보다 가독성이 더 좋고 Spark SQL Engine 최적화하기에도 좋음
SQL 사용방법 ( 데이터프레임 = df )
df.createOrReplaceTempView("Tablename")
group_df = spark.sql("""
SELECT gender, count(1) FROM Tablename GROUP BY
""")
print(group_df.collect())사용방법이 굉장히 간단하다.
테이블 이름 지정 --> 쿼리문 --> collect해서 출력
🟦 실습
PySpark 설치
!pip install pyspark==3.3.1 py4j==0.10.9.5
SparkSession 생성
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL #1") \
.getOrCreate()
1. JOIN 실습
vital = [
{ 'UserID': 100, 'VitalID': 1, 'Date': '2020-01-01', 'Weight': 75 },
{ 'UserID': 100, 'VitalID': 2, 'Date': '2020-01-02', 'Weight': 78 },
{ 'UserID': 101, 'VitalID': 3, 'Date': '2020-01-01', 'Weight': 90 },
{ 'UserID': 101, 'VitalID': 4, 'Date': '2020-01-02', 'Weight': 95 },
]
alert = [
{ 'AlertID': 1, 'VitalID': 4, 'AlertType': 'WeightIncrease', 'Date': '2020-01-01', 'UserID': 101},
{ 'AlertID': 2, 'VitalID': None, 'AlertType': 'MissingVital', 'Date': '2020-01-04', 'UserID': 100},
{ 'AlertID': 3, 'VitalID': None, 'AlertType': 'MissingVital', 'Date': '2020-01-05', 'UserID': 101}
]
# rdd에 올리기
rdd_vital = spark.sparkContext.parallelize(vital)
rdd_alert = spark.sparkContext.parallelize(alert)
# 데이터프레임화
df_vital = rdd_vital.toDF()
df_alert = rdd_alert.toDF()
#조인 조건
join_expr = df_vital.VitalID == df_alert.VitalID
# 왼쪽테이블 . join (오른쪽테이블, 조인 조건, 조인 종류)
df_vital.join(df_alert, join_expr, "inner").show()
데이터를 Spark에서 다루기 위해서는, 먼저 RDD에 올린뒤 데이터프레임화해줘야한다.

JOIN은 데이터프레임에 .join을 사용하고, 몇 가지 인자를 더해 조인한다.
코드에는 조인 조건(join_expr)으로 VitalID를 주고, 세 번째 인자로 "inner"를 넣음으로써 INNER JOIN을 만들었다.
세 번째 인자 조건으로는 left, right, full, cross를 넣을 수 있다.
SQL 쿼리문으로 조인을 할 수도 있다.
# 쿼리문을 사용하려면 테이블이 필요하다.
df_vital.createOrReplaceTempView("Vital")
df_alert.createOrReplaceTempView("Alert")
# INNER JOIN
df_inner_join = spark.sql("""
SELECT * FROM Vital v
JOIN Alert a ON v.vitalID = a.vitalID;
""")
df_inner_join.show()
이렇게 쿼리문을 사용하면 굉장히 간단하다.

2. GROUP BY , Window 함수실습
역시 SQL 쿼리문을 사용한다.
여기서는 user_session_channel, session_timestamp, session_transaction 테이블을 가져왔다.
- session_timestamp : sessionid(사용자 세션ID), ts(세션 시간)
- user_session_channel : userid, sessionid, channel(접속한 채널)
- session_transaction : sessionid, refunded(환불 유무), amount(구매 금액)
# GROUP BY로 월별, 채널별로 묶음
# 그리고 DISTINCT 한 userid로 방문자계산
mon_channel_rev_df = spark.sql("""
SELECT LEFT(sti.ts, 7) year_month,
usc.channel channel,
COUNT(DISTINCT userid) total_visitors
FROM user_session_channel usc
LEFT JOIN session_timestamp sti ON usc.sessionid = sti.sessionid
GROUP BY 1 ,2
ORDER BY 1, 2""")
평소 SQL문을 사용하듯이 쿼리문을 작성하면 된다.
월별 채널별 총 방문자(사용자는 유니크하게)를 계산하는 쿼리문이다!

더 복잡한 쿼리문도 가능하다.
mon_channel_rev_df = spark.sql("""
SELECT LEFT(ts, 7) month,
usc.channel,
COUNT(DISTINCT userid) uniqueUsers,
COUNT(DISTINCT (CASE WHEN amount >= 0 THEN userid END)) paidUsers,
SUM(amount) grossRevenue,
SUM(CASE WHEN refunded is not True THEN amount END) netRevenue,
ROUND(COUNT(DISTINCT CASE WHEN amount >= 0 THEN userid END)*100
/ COUNT(DISTINCT userid), 2) conversionRate
FROM user_session_channel usc
LEFT JOIN session_timestamp t ON t.sessionid = usc.sessionid
LEFT JOIN session_transaction st ON st.sessionid = usc.sessionid
GROUP BY 1, 2
ORDER BY 1, 2;
""")
월별 채널별 총 방문자(uniqueUsers), 매출 발생 방문자(paidUsers), 총 수익(grossRevenue), 순 수익(netRevenue), 구매 전환률(conversionRate)를 계산했다.

윈도우 함수도 사용해보자.
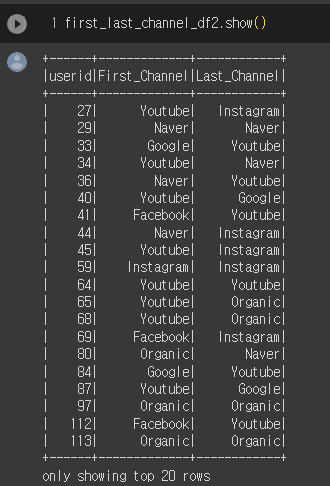
first_last_channel_df2 = spark.sql("""
SELECT DISTINCT A.userid,
FIRST_VALUE(A.channel) over(partition by A.userid order by B.ts
rows between unbounded preceding and unbounded following) AS First_Channel,
LAST_VALUE(A.channel) over(partition by A.userid order by B.ts
rows between unbounded preceding and unbounded following) AS Last_Channel
FROM user_session_channel A
LEFT JOIN session_timestamp B
ON A.sessionid = B.sessionid""")
userid에 대해 처음 접속한 채널(First_Channel)과 마지막 채널(Last_Channel)을 구하는 쿼리문이다.
FIRST_VALUE와 LAST_VALUE를 사용해서 간단하게 알아낼 수 있다.
🟩 Hive 메타스토어 사용하기
하이브는 테이블과 파티션과 관련된 메타정보를 모두 메타스토어에 저장한다. 이걸 Spark에서 사용해보자.
Spark 데이터베이스와 테이블에 대해 먼저 알아보자.
- 카탈로그 : 테이블과 뷰에 관한 메타 데이터 관리(메모리 기반, 하이브와 호환)
- 테이블 관리 방식 : 데이터베이스라 부르는 폴더안에 테이블이 저장되는 구조
- 스토리지 기반 테이블 :
- 기본적으로 HDFS와 Parquet 포맷을 사용
- Hive와 호환되는 메타 스토어 사용
- Managed Table, Unmanaged(External) Table 두 종류의 테이블이 존재(Hive와 동일)
- Managed Table
- dataframe.saveAsTable("테이블이름") or SQL(CTAS) -> HDFS에 저장
- spark.sql.warehouse.dir가 가르키는 위치에 데이터 저장, Unmanaged보다 성능좋음
- Unmanaged(External) Table
- 이미 HDFS에 존재하는 데이터에 스키마를 정의해서 사용
- 데이터가 이미 존재하므로 메타데이터만 카탈로그에 기록되며, 삭제되어도 데이터는 그대로임
- Managed Table
Spark에서는 SparkSession 생성시 enableHiveSupport() 호출하면 Hive와 호환되는 메타스토어 사용할 수 있다.
💻 Hive 메타스토어(Managed Table) Colab에서 실습해보기
# Hive 메타스토어를 사용하기 위해 .enableHiveSupport() 옵션 사용
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark Hive") \
.enableHiveSupport() \
.getOrCreate()
SparkSession 생성시 .enableHiveSupport()를 호출한다.
데이터로는 저장해둔 orders.csv 파일을 사용하였다.

# DB 생성
spark.sql("CREATE DATABASE IF NOT EXISTS TEST_DB")
spark.sql("USE TEST_DB")
#default는 기본적으로 생성되는 DB
spark.sql("SHOW DATABASES").show()
DB를 생성하고 나면, SHOW DATABASES를 사용해서 어떤 DB가 있는지 확인해보자.

DB를 생성한 뒤, ls로 내용을 확인해보자.

로컬에서 작업하므로 로컬 디스크를 HDFS로 사용한다. 이곳에 메타스토어(metastore_db)도 저장된다.
spark-warehouse는 DB폴더로써, Spark에서 Managed Table을 만들면 그 테이블의 데이터가 저장되는 곳이다.
그리고 TEST_DB에 orders를 테이블로 저장해보자.
# 테이블로 저장
df.write.saveAsTable("TEST_DB.orders", mode="overwrite")
그러면, spark-warehouse 폴더에 test_db.db/orders/ 경로로 데이터가 저장된다.

이 테이블의 내용을 확인하는 방법은 두 가지가 있다.
spark.sql("SELECT * FROM TEST_DB.orders").show(5)
spark.table("TEST_DB.orders").show(5)
둘 다 같은 결과가 나온다.
메타스토어 내용도 확인해보자.

spark 명령어로 테이블 리스트를 확인할 수도 있다.
# 테이블 리스트 확인
spark.catalog.listTables()

저장된 orders 테이블을 사용해서 CTAS로 새로운 테이블을 만들어보았다.

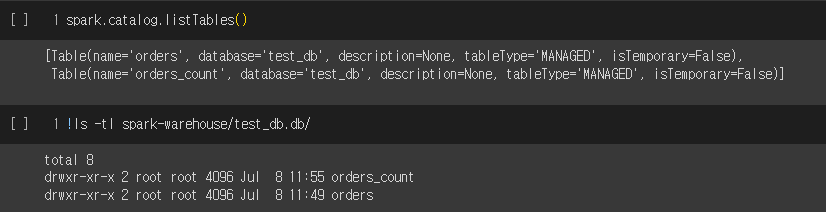
테이블이 정상적으로 하나 늘어난 것을 확인할 수 있다.
🟨 유닛 테스트 실습
코드 상의 특정 기능을 테스트하기 위해 작성되는 코드로, 정해진 입력을 주고 예상된 출력이 나오는지 확인한다.
전에 실습해보았던 Spark UDF를 사용해서, 각 함수의 기능을 테스트하는 코드를 작성해본다.
https://sunhokimdev.tistory.com/63
Spark UDF와 explode 기능 Colab에서 실습하기 - TIL230705
📚 KDT WEEK 14 DAY 3 TIL UDF UDAF Explode ⚒️ UDF - User Defined Function DataFrame이나 SQL에서 적용할 수 있는 사용자 정의 함수 Scalar 함수 : UPPER, LOWER ... Aggregation 함수(UDAF) : SUM, MIN, MAX Google Colab에서 실습을 진
sunhokimdev.tistory.com
파이썬의 유닛테스트 모듈을 기반으로 작성한다.
먼저, UDF를 작성한다.
from pyspark.sql.functions import pandas_udf
from pyspark.sql.types import *
import pandas as pd
# 대문자로 만드는 함수(UDF)
@pandas_udf(StringType())
def upper_udf_f(s: pd.Series) -> pd.Series:
return s.str.upper()
upperUDF = spark.udf.register("upper_udf", upper_udf_f)
그리고 다른 python 파일에 테스트 코드를 작성하는 것이 좋지만,
colab 환경에서 실습하기 때문에 동일한 파일에서 테스트 클래스를 만들었다.
from unittest import TestCase
class UtilsTestCase(TestCase):
spark = None
# Test가 시작하면서 자동으로 처음 불러오는 함수
# SparkSession을 하나 만들어서 spark에 저장한다.
# 다른 함수에서는 이걸 self로 가져올 수 있다.
@classmethod
def setUpClass(cls) -> None:
cls.spark = SparkSession.builder \
.appName("Spark Unit Test") \
.getOrCreate()
# 테스트 함수
def test_upper_udf(self):
test_data = [
{ "name": "John Kim" },
{ "name": "Johnny Kim"},
{ "name": "1234" }
]
expected_results = [ "JOHN KIM", "JOHNNY KIM", "1234" ]
upperUDF = self.spark.udf.register("upper_udf", upper_udf_f)
test_df = self.spark.createDataFrame(test_data)
names = test_df.select("name", upperUDF("name").alias("NAME")).collect()
results = []
for name in names:
results.append(name["NAME"])
self.assertCountEqual(results, expected_results)
# 마지막에 호출되는 함수이다.
# setUpClass에서 할당된 자원이 있다면 여기서 자동으로 마지막에 릴리스해주는 역할을 한다.
@classmethod
def tearDownClass(cls) -> None:
cls.spark.stop()
파이썬의 unittest에서 TestCase를 import해서 사용한다.
테스트가 시작되면 setUpClass 함수를 먼저 호출하게 된다.
여기서 SparkSession을 만들면 되고, 테스트에 필요한 리소스가 있다면 여기서 할당하면 된다.
test_upper_udf 함수를 통해 테스트를 하게 되는데,
간단히 생각하면 test_data가 upperUDF를 거쳐서 expected_results가 되는지 확인하는 과정이다.
여기서 assertCountEqual이 두 개의 리스트를 받아 리스트를 Sorting했을 때 동일한 지 확인해주게 된다.
이제 테스트를 실행해보자.
import unittest
unittest.main(argv=[''], verbosity=2, exit=False)
'TIL' 카테고리의 다른 글
| Spark에서 Parquet 다루기 실습 + Execution Plan 알아보기 - TIL230706 (0) | 2023.07.09 |
|---|---|
| Spark UDF와 explode 기능 Colab에서 실습하기 - TIL230705 (0) | 2023.07.09 |
| Spark 데이터처리 실습 2 (컬럼명과 타입 추가하기 + 정규표현식 + Pandas와 비교)- TIL230704 (0) | 2023.07.06 |
| Spark 데이터처리 실습 - TIL230704 (0) | 2023.07.05 |
| 빅데이터와 Spark 알아보기 - TIL230703 (0) | 2023.07.04 |



