
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- aws
- Spark Partitioning
- Kafka
- Airflow
- Docker
- AQE
- SQL
- Speculative Execution
- colab
- disk spill
- off heap memory
- 데이터 파이프라인
- Spark
- Spark 실습
- Salting
- Kubernetes
- etl
- mysql
- 빅데이터
- Spark Caching
- backfill
- topic
- Spark SQL
- spark executor memory
- CI/CD
- DataFrame Hint
- KDT_TIL
- Dag
- k8s
- redshift
- Today
- Total
JUST DO IT!
Spark 데이터처리 실습 - TIL230704 본문
📚 KDT WEEK 14 DAY 2 TIL
- Spark 데이터처리
- Spark 데이터구조
🟥 Spark 데이터처리
- 빅데이터의 효율적 처리 ➡️ 병렬처리 ➡️ 데이터의 분산 필요
- 하둡 맵의 데이터 처리단위는 데이터 블록(128MB, 조절가능)
- Spark에서는 이 데이터 블록을 파티션(Partition)이라고 부른다.
적절한 파티션의 수 : Executor의 수 x Executor의 CPU의 수 ➡️ 병렬 처리 최대화
♒ Spark 데이터 처리 흐름
데이터프레임은 작은 파티션들로 구성된다.
입력 데이터프레임을 원하는 결과가 나올 때까지 다른 데이터 프레임으로 계속 변환되는 과정으로 흐른다.
ex) sort, group by, filter, map, join.. 등의 함수로 인해 계속 변환되는 것!

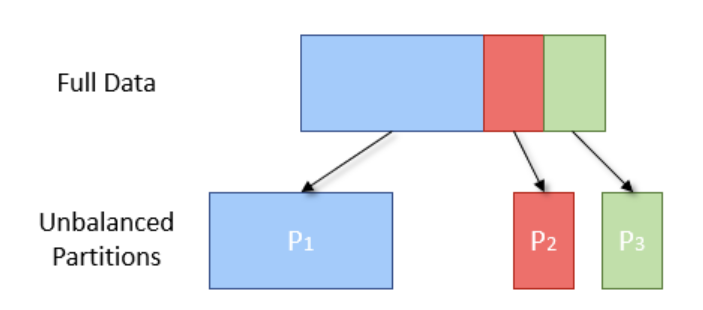
🔄️ 셔플링
위에서 group by, sort 같은 오퍼레이션들은 새로운 파티션이 만들어짐에따라 파티션간의 데이터 이동 필요하다.
새로운 파티션에 데이터를 이동시키는 과정에 따라 Data Skewness가 발생하기 쉽다.
따라서 셔플링을 최소화하고 파티션을 최적화하는 것이 중요하다.
🟦 Spark 데이터 구조
Spark 데이터는 Immutable(불변하고) Distributed(분산된) 데이터이다.
먼저 데이터 종류로는 RDD, DataFrame, Dataset이 있다.
RDD(Resilient Distributed Dataset)
- 로우레벨 데이터로, 클러스터내의 서버에 분산된 데이터를 지칭
- 레코드별로 존재하지만 스키마가 따로 존재하지 않아 구조화된 데이터나 비구조화된 데이터 모두 지원
- RDD는 다수의 파티션으로 구성되며, 로우레벨의 함수형 변환(map, filter, flatMap 등)을 지원한다.
- 일반 파이썬 데이터(리스트)를 parallelize와 collect 함수를 통해 RDD로 변환하거나 다시 되돌릴수 있다.
DataFrame과 Dataset
- RDD위에 존재하는 하이레벨 데이터로, RDD와는 달리 필드 정보를 갖고 있음(테이블)
- Dataset은 타입 정보가 존재하여 컴파일 언어(Scala/Java) 사용가능
- PySpark에서는 DataFrame(판다스 데이터 프레임과 흡사) 사용
🏗️ Spark 프로그램 구조
SparkSession
- Spark 프로그램의 시작 ➡️ SparkSession을 만드는 것(Singleton)
- Dataframe, SQL, Streaming, ML API 모두 이 객체로 통신
- RDD 관련된 작업에는 sparkContext 객체 사용

Spark Session 환경 변수
- spark.executor.memory : executor별 메모리
- spark.executor.cores : executor별 CPU 수
- spark.driver.memory : driver 메모리
- spark.sql.shuffle.partitions : Shuffle후 Partiton의 수(최대값)
등 여러가지를 조율할 수 있고, 이는 SparkSession을 생성하면서 설정해줄 수 있다.
환경 변수 설정 방법
from pyspark.sql import SparkSession
# SparkSession은 싱글턴
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Tutorial')\
.config("spark.some.config.option1", "some-value") \ # 환경 설정이름, 설정 값 형태로 설정
.config("spark.some.config.option2", "some-value") \
.getOrCreate()
또는
from pyspark.sql import SparkSession
from pyspark import SparkConf
# 환경 변수
conf = SparkConf()
conf.set("spark.app.name", "PySpark Tutorial")
conf.set("spark.master", "local[*]")
# SparkSession
spark = SparkSession.builder\
.config(conf=conf) \ # 여기서 환경 변수 지정
.getOrCreate()
Spark Session이 지원하는 데이터 소스
- HDFS 파일(csv, json, orc, text, parquet...)
- HIVE 테이블
- JDBC 관계형 DB
- 클라우드 기반 데이터 시스템
- 스트리밍 시스템
- 그 외 소스 : https://spark.apache.org/docs/latest/sql-data-sources.html
Data Sources - Spark 3.4.1 Documentation
spark.apache.org
- spark.read(DataFrameReader)를 사용하여 데이터프레임으로 로드
- spark.write(DataFrameWriter)를 사용하여 데이터프레임을 저장
🟩 Spark 실습
실습 환경은 Google Colab에서 Spark Cluster Manager로 local[n]을 지정하여 Local Standalone Spark을 사용한다.
이 환경은 주로 개발이나 간단한 테스트 용도로 사용되는 환경이며, JVM에서 모든 프로세스를 실행하게 된다.
Spark Web UI는 기본적으로 접근 불가하고, Py4J를 추가로 설치하여 파이썬에서 JVM의 자바 객체를 사용 가능하게 한다.
Colab에서 아래의 명령어를 입력하여 Pyspark와 py4j를 사용한다.
!pip install pyspark==3.3.1 py4j==0.10.9.5
먼저, Spark를 사용하기 위해 SparkSession을 새로 하나 생성한다.
SparkSession을 생성하면서 local[*]을 지정하면 된다.
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\ # LocalMode, 컴퓨터의 CPU의 수만큼 쓰레드를 Executor에 생성
.appName('PySpark Tutorial')\
.getOrCreate() # SparkSession은 Singleton 객체로, 여러개를 만들지 않는다.

1. Python 객체 RDD로 변환하기
데이터로는 리스트안에 String형태로 json을 저장하였다.
이 데이터를 parallelize 함수로 RDD 변환, collect 함수로 다시 되돌릴 수 있다.
아래 코드에서는 parallelize > map(json 파싱) > collect 과정을 통해 데이터가 가공되는 과정을 거치게된다.
name_list_json = [ '{"name": "keeyong"}', '{"name": "benjamin"}', '{"name": "claire"}' ]
rdd = spark.sparkContext.parallelize(name_list_json) # parallelize 함수로 RDD 변환
rdd.count() # rdd에 저장된 데이터 개수 출력
import json
parsed_rdd = rdd.map(lambda el:json.loads(el)) # json으로 파싱
parsed_rdd.collect() # collect 함수로 가져올 수 있음, json으로 파싱된 형태로 가져온다.
parsed_name_rdd = rdd.map(lambda el:json.loads(el)["name"]) # 이런 형태도 가능
parsed_name_rdd.collect()
실행 결과

parsed_rdd만으로는 데이터가 출력되지 않는 걸 볼 수 있다.
.collect() 함수를 사용해서 RDD에서 다시 이쪽으로 가져오는 과정이 필요한 것이다.
2. 파이썬 리스트를 데이터 프레임으로 변환
.createDataFrame() 함수를 사용하면, 데이터프레임으로 변환할 수 있다.
from pyspark.sql.types import StringType
# 두 번째 인자로 스키마 지정, 일단 StringType으로 지정한다.
# 이 경우, 기본적으로 value라는 필드로 생성된다. (실행 결과 참고)
df = spark.createDataFrame(name_list_json, StringType())
df.count() # 데이터 개수
df.printSchema() # 스키마 확인 가능
df.select('*').collect() # 모든 데이터 확인

3. RDD를 DataFrame으로 변환
RDD 데이터의 경우 .toDF() 함수를 사용하면 데이터프레임이 된다.
df_parsed_rdd = parsed_rdd.toDF() # parsed_rdd는 아까 json으로 파싱된 형태로, toDF 함수로 간단히 변환 가능
df_parsed_rdd.printSchema() # 스키마 확인
df_parsed_rdd.select('name').collect()

4. csv 파일을 Spark 데이터 프레임으로 로드해보기
df = spark.read.option("header", True).csv("name_gender.csv") # 헤더가 있으면 이렇게해야 정상인식
df.printSchema() # 스키마 확인
df.show() # 테이블 확인
df.head(5) # 위에서부터 데이터 5개 확인
df.groupby(["gender"]).count().collect() # groupby 사용하기, collect를 꼭 써야 보인다.

5. 데이터프레임을 테이블뷰로 만들어서 SparkSQL 처리하기
spark.sql을 사용하면 바로 쿼리문을 적용할 수도 있다.
df.createOrReplaceTempView("namegender") # df를 마치 테이블처럼 사용, 이름을 namegender로 설정
namegender_group_df = spark.sql("SELECT gender, count(1) FROM namegender GROUP BY 1") # 쿼리문으로 데이터 프레임 생성
namegender_group_df.collect() # collect를 통해 가져오기
spark.catalog.listTables() # 테이블 보기

6. 파티션 수 계산해보고, 리파티션해보기
namegender_group_df.rdd.getNumPartitions() # 파티션이 하나인걸 확인
two_namegender_group_df = namegender_group_df.repartition(2) # 별다른 지정이 없으면 랜덤하게 두 개로 나눔
two_namegender_group_df.rdd.getNumPartitions() # 이번에는 두 개인 것을 확인

'TIL' 카테고리의 다른 글
| Colab에서 Spark SQL 간단 실습해보기(+ Hive 메타스토어) - TIL230705 (0) | 2023.07.09 |
|---|---|
| Spark 데이터처리 실습 2 (컬럼명과 타입 추가하기 + 정규표현식 + Pandas와 비교)- TIL230704 (0) | 2023.07.06 |
| 빅데이터와 Spark 알아보기 - TIL230703 (0) | 2023.07.04 |
| 데이터 카탈로그 - TIL230623(2) (0) | 2023.06.23 |
| DBT의 추가 기능 알아보기 (seed, sources, snapshots, tests) - TIL230623 (0) | 2023.06.23 |


