
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Spark Partitioning
- 데이터 파이프라인
- Kubernetes
- k8s
- Spark
- Docker
- CI/CD
- Speculative Execution
- spark executor memory
- colab
- Airflow
- Spark 실습
- Kafka
- KDT_TIL
- redshift
- 빅데이터
- aws
- Spark Caching
- mysql
- AQE
- Spark SQL
- disk spill
- etl
- backfill
- Dag
- Salting
- off heap memory
- DataFrame Hint
- SQL
- topic
- Today
- Total
JUST DO IT!
Spark에서 Parquet 다루기 실습 + Execution Plan 알아보기 - TIL230706 본문
📚 KDT WEEK 14 DAY 4 TIL
- Spark 파일포맷(Parquet)
- Spark Execution Plan
- Bucketing과 File System Partitioning
🟥 Spark 파일포맷
Parquet : Spark의 기본 파일 포맷
Parquet 페이지 : http://parquet.incubator.apache.org/
Apache Parquet
The Apache Parquet Website
parquet.incubator.apache.org
Parquet은 Structured 포맷으로, 압축된 바이너리 파일이며 내부에 스키마 정보(필드 타입까지)를 가진 파일 포맷이다.
Structured ex) Parquet, AVRO, ORC, SequenceFile ...
💻 실습(Colab)
사용할 환경 설치
!pip install pyspark==3.3.1 py4j==0.10.9.5
Spark Session 생성 - avro 포맷을 사용하려면 따로 지정필요
from pyspark.sql import *
from pyspark.sql.functions import *
# avro 포맷은 Spark에 별도로 지정이 필요하다.
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("Spark Writing Demo") \
.master("local[3]") \
.config("spark.jars.packages", "org.apache.spark:spark-avro_2.12:3.3.1") \
.getOrCreate()
데이터를 위한 csv 파일 로딩
# 가지고 있던 appl_stock.csv 파일 로딩
df = spark.read.format("csv").load("appl_stock.csv")
csv파일이 로딩된 df의 파티션 개수, 레코드 개수를 알아보자.
print("Num Partitions before: " + str(df.rdd.getNumPartitions())) # 몇 개의 파티션이 있는지?
df.groupBy(spark_partition_id()).count().show() # 파티션별로 몇 개의 레코드가 있는지?
- .rdd.getNumPartitions() : 해당 데이터프레임의 파티션 개수 얻기
- spark_partition_id : 데이터프레임을 구성하는 파티션별로 아이디 리턴
df를 사용해서 df2에 네 개의 파티션, df3에 두 개의 파티션을 가지도록 설정
df2 = df.repartition(4) # 리파티션해서 네 개로 만들어줌
df3 = df2.coalesce(2) # 파티션의 수를 줄여줌(셔플링을 최소화하는 방향으로)

그리고 df, df2, df3를 각각 avro, parquet, json으로 저장해보자.
# df : 파티션이 하나였던 것
# avro로 세이브
# 옵션으로 path 지정가능
df.write \
.format("avro") \
.mode("overwrite") \
.option("path", "dataOutput/avro/") \
.save()
# df2 : 파티션이 네 개였던 것
# parquet 로 세이브
df2.write \
.format("parquet") \
.mode("overwrite") \
.option("path", "dataOutput/parquet/") \
.save()
# df3 : 파티션이 두 개였던 것
# json 로 세이브
df3.write \
.format("json") \
.mode("overwrite") \
.option("path", "dataOutput/json/") \
.save()
그리고 ls 명령어 사용해서 확인해보면, 각 포맷별로 폴더가 저장되고 그 안에 데이터가 저장된다.

각 내용을 확인하면 다음과 같다.

parquet의 경우 snappy가 뒤에 붙어서 압축된 것을 확인할 수 있다.
주석에도 쓰여있듯 snappy는 spiltable한 압축 형태로, 압축이 되었어도 블록단위로 나눌 수 있는 유용한 압축 단위이다.
이번에는 Parquet 파일포맷의 Schema Evolution 기능을 사용해보자.
각기다른 스키마를 가진 세 개의 Parquet 파일을 가져온다고 가정하자.
각 parquet 파일이 저장되어있고, 불러와서 데이터를 show() 하였다.


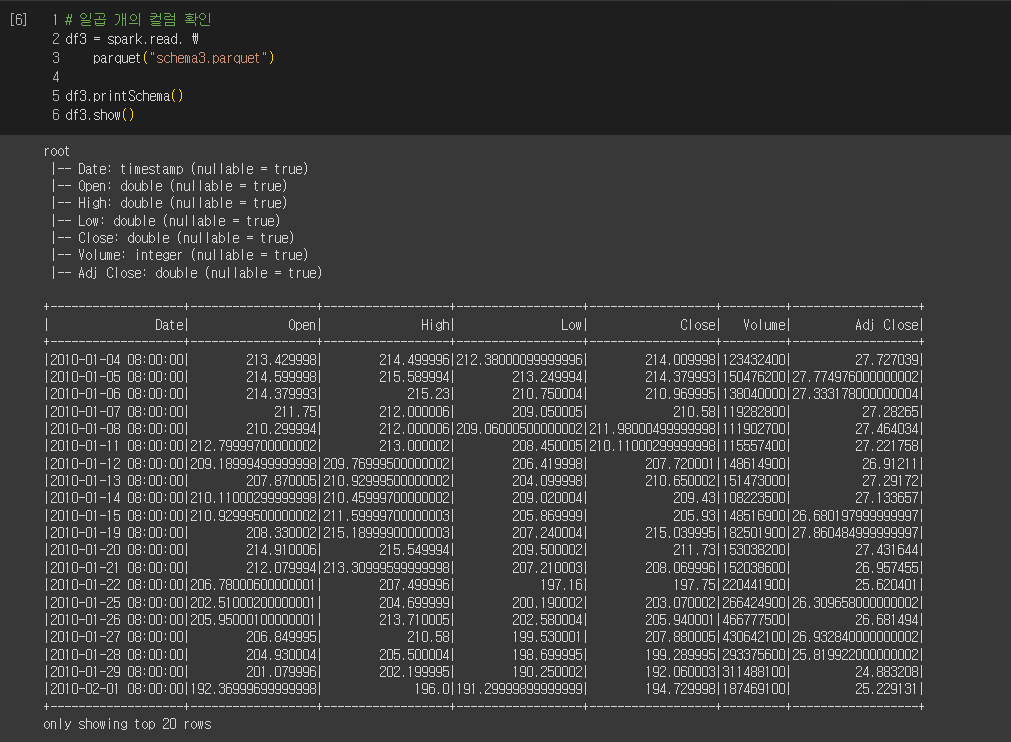
이미지에서 보이듯 각 parquet 파일은 하나의 컬럼이 추가되는 형식으로 스키마가 다르다.
Parquet은 Schema Evolution을 지원하기 때문에 이를 마치 하나의 스키마처럼 한번에 불러올 수가 있다.

.option("mergeSchema", True) 옵션을 사용해서 Schema Evolution 기능을 사용하였다.
schema1이 원래 가지고 있던 데이터처럼 추가된 컬럼에 데이터가 없으면 NULL로 채워진다.

🟦 Spark의 Execution Plan
📅 Execution Plan : 개발자가 작성한 코드를 Spark이 어떻게 실제로 실행을 하는가?
Spark에서 데이터 프레임을 where, groupby, select 등으로 처리할 때, 명령어마다 바로바로 처리하지 않는다.
해당 작업들을 모아두었다가, show()나 collect() 등을 통해 데이터를 직접 보여줘야할 때 한꺼번에 처리하게 된다!
이때 데이터 프레임에 직접 작업을 하는 명령어들을 Transformations라고 하고,
show()나 collect()처럼 보여주거나 Read, Write처럼 데이터 처리가 완료되어야 작업이 가능한 명령어를 Actions라고 한다.
1. Transformations
- Narrow Dependencies : 독립적인 Partition level 작업 / 셔플링 x
- select, filter, map 등등
- Wide Dependencies : 셔플링이 필요한 작업
- groupby, reduceby, partitionby, repartition, coalesce 등등
2. Actions
- Read, Write, Show, Collect : Job을 실행시켜 실제 코드가 실행되는 명령어
- Lazy Execution : Job을 하나 만들어내고 코드를 실제로 수행
- 최대한 더 많은 오퍼레이션을 모아두었다가 한번에 최적화를 해야 더 효율적이기 때문!
🧱 기본 구조 : Action > Job > 1 + Stages > 1 + Tasks
- Action : Job을 하나 만들어내고, 코드가 실제로 실행됨
- Job : 하나 혹은 그 이상의 Stage로 구성된다.
- Stage는 셔플링이 발생하는 경우 새로 생긴다. ex) groupby
- Stage : DAG 형태로 구성된 Task들이 존재하여 병렬 실행된다.
- Task : 가장 작은 실행 유닛으로, Executor에 의해 실행된다.
💻 실습(Colab)
1. WordCount.py
from pyspark.sql import *
from pyspark.sql.functions import *
# spark.sql.adaptive.enabled : Fasle는 이해하기 어려운 최적화는 Unable
spark = SparkSession \
.builder \
.master("local[3]") \
.appName("SparkSchemaDemo") \
.config("spark.sql.adaptive.enabled", False) \
.getOrCreate()
spark.conf.set("spark.sql.shuffle.partitions", 3)
# 여기의 read의 경우 헤더를 확인하지 않기 때문에 JOB을 실행하지는 않음
# 헤더를 확인해야 할 때만 데이터를 직접 확인하므로 JOB을 실행
df = spark.read.text("shakespeare.txt")
# value(기본 컬럼명)을 공백을 기준으로 나누어 word 컬럼에 각각 넣고, 그 개수를 새는 SQL
df_count = df.select(explode(split(df.value, " ")).alias("word")).groupBy("word").count()
df_count.show()
input("stopping ...")

Groupby 때문에 새로운 Stage가 생성된 것을 알 수 있다.
2. JOIN.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import broadcast
spark = SparkSession \
.builder \
.appName("Shuffle Join Demo") \
.master("local[3]") \
.config("spark.sql.shuffle.partitions", 3) \
.config("spark.sql.adaptive.enabled", False) \
.getOrCreate()
# json 파일의 read는 스키마를 알기 위해 읽어야하므로 read는 ACTION이 된다.
df_large = spark.read.json("large_data/")
df_small = spark.read.json("small_data/")
join_expr = df_large.id == df_small.id
join_df = df_large.join(df_small, join_expr, "inner")
join_df.collect()
input("Waiting ...")
spark.stop()

각각 json을 파일을 불러오는 job에서 Stage를 하나씩 갖게 되고, JOIN을 통해 Stage를 하나 더 생성하게 된다.
위의 이미지가 기본적인 JOIN의 Execution Plan 형태가 된다.
🟩 Bucketing과 File System Partitioning
데이터 저장을 이후 반복처리에 최적화된 방법으로 하는 것이 목적으로, Hive 메타스토어 사용이 필요하다.
1. Bucketing
- DataFrame을 특정 ID 기준으로 나눠서 테이블로 저장
- 한번의 셔플링이 필요하나, 나중에 다수 셔플링을 방지하기 위한 대비책이 됨
- 데이터의 특성을 잘 알고있는 경우네 사용이 가능하다.
Aggregation, Window 함수, JOIN에서 많이 사용되는 컬럼이 있는지 검사 > 이 컬럼을 기준으로 테이블 저장
2. File System Partitioning = Hive의 Partitioning
- 데이터의 특정 컬럼들을 기준으로 폴더 구조를 만들어 데이터 저장을 최적화 > 로딩, 필터링의 오버헤드 줄임
- Partition Key : 폴더 구조를 만들 특정 컬럼
- DataFrameWriter의 partitionBy 사용
- Partiton Key는 Cardinality가 적은 컬럼이 좋다.
ex) 로그 파일은 데이터 생성시간 기반으로 데이터 읽기를 많이 하게 됨.
이 로그 파일이 굉장히 크다면 데이터 자체를 연도-월-일의 폴더 구조로 저장하는 것! > 읽기 과정 최소화, 관리 쉬움
'TIL' 카테고리의 다른 글
| Kafka 알아보고 설치해보기 - TIL230712 (0) | 2023.07.14 |
|---|---|
| 빅데이터의 실시간 처리 -TIL230710 (0) | 2023.07.11 |
| Spark UDF와 explode 기능 Colab에서 실습하기 - TIL230705 (0) | 2023.07.09 |
| Colab에서 Spark SQL 간단 실습해보기(+ Hive 메타스토어) - TIL230705 (0) | 2023.07.09 |
| Spark 데이터처리 실습 2 (컬럼명과 타입 추가하기 + 정규표현식 + Pandas와 비교)- TIL230704 (0) | 2023.07.06 |



